深度学习(deep learning)通过监督学习(supervised learning)在大量的机器学习任务上取得了瞩目的成就,如ImageNet上超过 90% 的分类准确率,Cityscapes 上超过 85% 的分割准确率。然而,实现高精度的分类、分割等任务需要大规模有标签的训练数据,如ImageNet的百万张图像或是Cityscapes上数千张1080p分辨率图像的像素级标注,都需要耗费大量的人力物力,同时在这些数据上训练的模型往往在跨域的数据泛化上仍然具有挑战性(如医学图像)。虽然数据标注难以获取,但从多种渠道收集无标注数据是相对容易的, 因此研究者逐渐把目光转向如何利用少部分有标注数据和大规模的无标注数据来训练模型 (比如, 有标签数据占整体的 1-10%)。这种同时利用少量有标注数据和大量无标注数据训练模型的方法称为半监督学习(semi-supervised learning, SSL)。
SSL可以大致分为以下几种类别:
| Type | Description |
|---|---|
| Consistency Regularization | 一致性正则化:即对数据进行扰动,特征/预测结果不应有显著性变化。从而通过约束扰动前后的数据对应的特征来训练模型 |
| Entropy Minimization | 熵极小化:鼓励模型预测高置信度的结果 |
| Proxy-Label Method | 伪标签方法:通过一个预训练模型对无标签数据进行打标签操作,然后进一步利用打了标签的数据训练模型 |
| Generative Models | 生成式模型:结合GAN或VAE,从无标签数据中学习好的用于分类的判别器 |
| Graph-Based Methods | 基于图的方法:有标签数据和无标签数据可以看做图的节点,目标是通过节点之间的相似性把有标签节点的标签传播到无标签节点 |
本次综述主要围绕混合方法(Hybrid Methods)展开,混合方法也可以称为整体性方法(Holistic Methods),它是把 SSL 已有的不同路线的SOTA方法集成起来的一类方法,代表性的工作主要是Google一系列的*Match方法。
方法
MixMatch
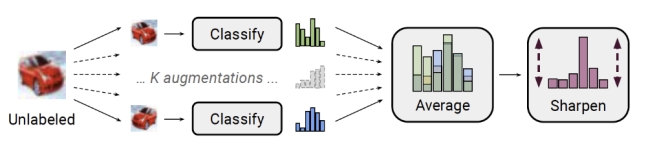
图1:MixMatch
MixMatch这个方法结合了熵极小化(entropy minimization),一致性正则化(consistency regularization)以及通用正则化(generic regularization)这几项作为整体损失项。算法如下伪代码所示:

概括来说,MixMatch的主要流程为:首先对于有标签和无标签的数据进行数据增广,然后基于k个增强后的无标签数据进行预测平均的结果并结合一个锐化的操作生成伪标签,之后对所有数据使用mixup,基于mixup后的新的数据计算损失,损失包含两部分一部分是有标签数据的损失另一部分为无标签数据的损失。
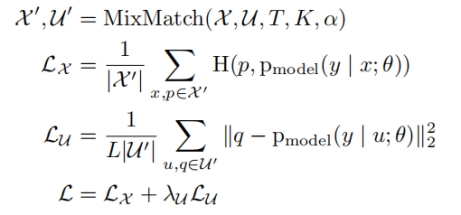
优缺点:这篇2019年的论文将一些SSL方法融合起来,取得了当时的SOTA效果。但是在这个方法里面整个模型的数据空间和标签空间非常耦合(虽然效果不错),需要设定的超参数(锐化操作的温度稀疏等)较多,并且过程相较于之后提出的FixMatch方法繁琐许多,但作为*Match系列半监督方法的第一篇还是具有开创性意义。
ReMixMatch
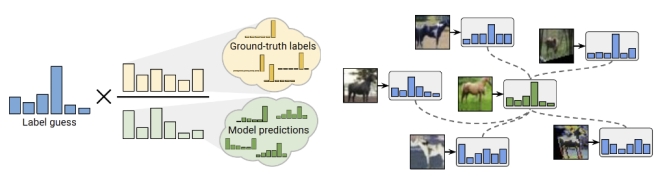
图 2 ReMixMatch: distribution alignment 和 augmentation anchoring;
左:预测的标签分布是根据经验性的ground-truth类分布除以未标记数据上的平均模型预测的比率来调整。
右:使用对弱增强图像的预测(绿色,中间)作为对同一图像的强增强(蓝色)的预测目标。
ReMixMatch是在MixMatch方法上的改进,它在MixMatch 的基础上引入了两个新技术:1.*分布对齐 (distribution alignment):* 要求无标签数据的预测(边缘)分布要对齐有标签数据的(边缘)分布,也就是利用ground-truth类别的比例去调整无标签类别的比例;2.*增广锚定 (augmentation anchoring):* 要求多个强增广数据的预测接近弱增广数据的预测 (锚点)。
优缺点:ReMixMatch比以前的工作明显更节省标注数据,相比MixMatch只需要1/5到1/16倍的数据来达到相同的精度。但是对比之后提出的FixMatch方法,过程还是比较繁琐。
FixMatch
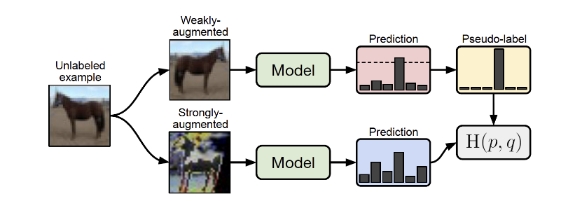
图 3 FixMatch的示意图:一个弱增强的图像(顶部)被送入模型以获得预测(红框)。当模型给任何类别分配的概率高于阈值(虚线)时,预测就会被转换为一个热的伪标签。然后计算该模型对同一图像的强增强版本的预测(底部)。模型通过交叉熵损失使其对强增强版本的预测与伪标签相匹配。
FixMatch发表在NIPS 2020,结合了伪标签和一致性正则化,同时相比于Mixup极大地简化了整个方法。FixMatch基于模型对弱增强的无标签z图片的预测生成伪标签,并且只选用了高置信度的预测样本。对于这批高置信度样本,基于一致性正则化的思想,使模型对强增强的图片获得一致的预测。尽管流程简单,FixMatch在一系列标准半监督学习数据集上得到了SOTA的性能。
优缺点:对于无标签数据, 如果模型弱增强样本的预测类别的置信度大于一个阈值,则该类别当做伪标签用于训练强增强的样本,FixMatch中的这种策略可以确保只有高质量的无标签数据对模型训练有贡献。但是FixMatch依靠一个固定的阈值来计算无监督的损失,是一个超参数,但它忽略了相当数量的其他无标签数据,特别是在训练过程的早期阶段,只有少数无标签数据的预测置信度高于阈值。
FlexMatch
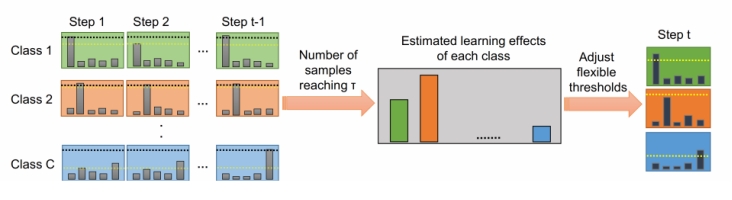
图 4 CPL方法流程示意图。从图中左侧可以看到CPL考虑了所有的类的所有历史时刻的样本的置信度,对每个类会统计所有超过\(\tau\)的样本数量,其中就\(\tau\)是FixMatch中使用的固定高阈值,将统计出的数量作为学习效果预估,并最终用其来调整动态阈值。
FlexMatch是发表于NeurIPS2021的一项工作,该方法将基于FixMatch进行了一定的改进。FixMatch依靠一个固定的阈值来计算无监督的损失来确保只有高质量的无标签数据对模型训练有贡献,这种固定的高阈值存在一定问题:第一,对于分类任务而言,不同的类别的学习难度是不同的,模型在某一时刻对各类的学习情况也是不同的。第二,在训练的起步阶段,受随机初始化影响,模型很可能把数据都盲目地预测到一个类里面去并且置信度很高。
为了解决这些问题,FlexMatch提出了课程伪标签(Curriculum Pseudo Labeling,CPL),这是一种课程学习策略,用灵活的阈值代替了预先定义的阈值,这些阈值根据当前的学习状态对每个类别进行动态调整。值得注意的是,这个过程没有引入任何额外的参数(超参数或可训练参数)或额外的计算(正向或反向传播)。
优缺点:FlexMatch中的CPL策略填补了现代SSL算法在训练过程中没有考虑不同类的内在学习难度的空白,并表明通过这样做,收敛速度和最终的准确性都可以得到提高,同时极其简单且几乎没有成本。结合FixMatch和CPL的FlexMatch方法在各种SSL benchmarks上实现了最先进的性能,特别当标签数据极其有限或任务具有挑战性时,其表现也很不错。改进方向就像这篇论文的作者提及的,可以更多地探索长尾数据分布下的半监督方法,在这种情况下,属于每个类别的未标记数据是非常不平衡的。
拓展优化
cv领域中简单但性能良好的半监督机器学习算法的存在有助于让机器学习模型被部署在标签昂贵或难以获得的实际领域中。现实场景中,数据分布非常不平衡并且质量良莠不齐,同时在SSL方面取得了快速的进展,这种进步的代价是越来越复杂的学习算法,而这对应复杂的损失项和许多难以调节的超参数,这些阻碍了SSL的进一步应用,因此SSL的可能研究方向为探索更加鲁棒的算法以及具体场景的应用。
Reference
[1] Berthelot, David, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, and Colin Raffel. “Mixmatch: A holistic approach to semi-supervised learning.” arXiv preprint arXiv:1905.02249 (2019).
[2] Berthelot, David, Nicholas Carlini, Ekin D. Cubuk, Alex Kurakin, Kihyuk Sohn, Han Zhang, and Colin Raffel. “Remixmatch: Semi-supervised learning with distribution alignment and augmentation anchoring.” arXiv preprint arXiv:1911.09785 (2019).
[3] Sohn, Kihyuk, David Berthelot, Chun-Liang Li, Zizhao Zhang, Nicholas Carlini, Ekin D. Cubuk, Alex Kurakin, Han Zhang, and Colin Raffel. “Fixmatch: Simplifying semi-supervised learning with consistency and confidence.” arXiv preprint arXiv:2001.07685 (2020).
[4] Zhang, Bowen, Yidong Wang, Wenxin Hou, Hao Wu, Jindong Wang, Manabu Okumura, and Takahiro Shinozaki. “Flexmatch: Boosting semi-supervised learning with curriculum pseudo labeling.” Advances in Neural Information Processing Systems 34 (2021).