由于终端用户设备的计算和传感能力的提高,以及对用户隐私的日益关注,联邦学习 (FL) 已成为一种有前景的分布式机器学习 (ML) 技术。根据数据划分方式可以将联邦学习范式分为三种场景,包括横向联邦学习(Horizontal FL,HFL)、纵向联邦学习(vertical FL ,VFL )和联邦迁移学习。
大多数现有工作都集中在横向 FL (HFL) 上,它要求所有参与者拥有相同的属性空间但不同的样本空间(更多相关内容可以参考这篇博客),而纵向联邦学习要求的是所有参与者拥有相同的样本空间和不同的属性空间 ,可以使得具有垂直划分数据的非竞争组织/实体进行协作,例如,银行、保险公司和电子商务平台进行协作,改进对所学习用户的生活/购物行为进行预测的模型性能。其典型的使用场景之一是几个参与者(组织)协作训练一个具有垂直划分数据的模型,但这些属性的标签仅由一个参与者拥有。例如,一家用户属性有限的汽车保险公司可能希望通过合并来自其他企业(例如银行、税务局等)的更多属性来改进风险评估模型。其他参与者的作用只是提供额外的特征信息不直接向其他参与者披露他们的数据,获得一定的奖励作为回报。与直接共享数据相比,VFL 需要的来自参与客户的资源更少,从而能够实现轻量级和可扩展的分布式训练解决方案。
本文主要围绕”Wei, Kang, et al. “Vertical federated learning: Challenges, methodologies and experiments.” arXiv preprint arXiv:2202.04309 (2022).”论文内容进行简化和梳理,主要目的是方便自己了解VFL的相关研究。接下来主要对VFL以下几方面内容进行介绍:
- VFL基本模型
- VFL和HFL之间的主要区别
- VFL中的挑战
- 应对挑战的可能解决方案
本文由本人整理完成,引用的话标注来源,欢迎随意转载阅读^ - ^
1. VFL模型框架
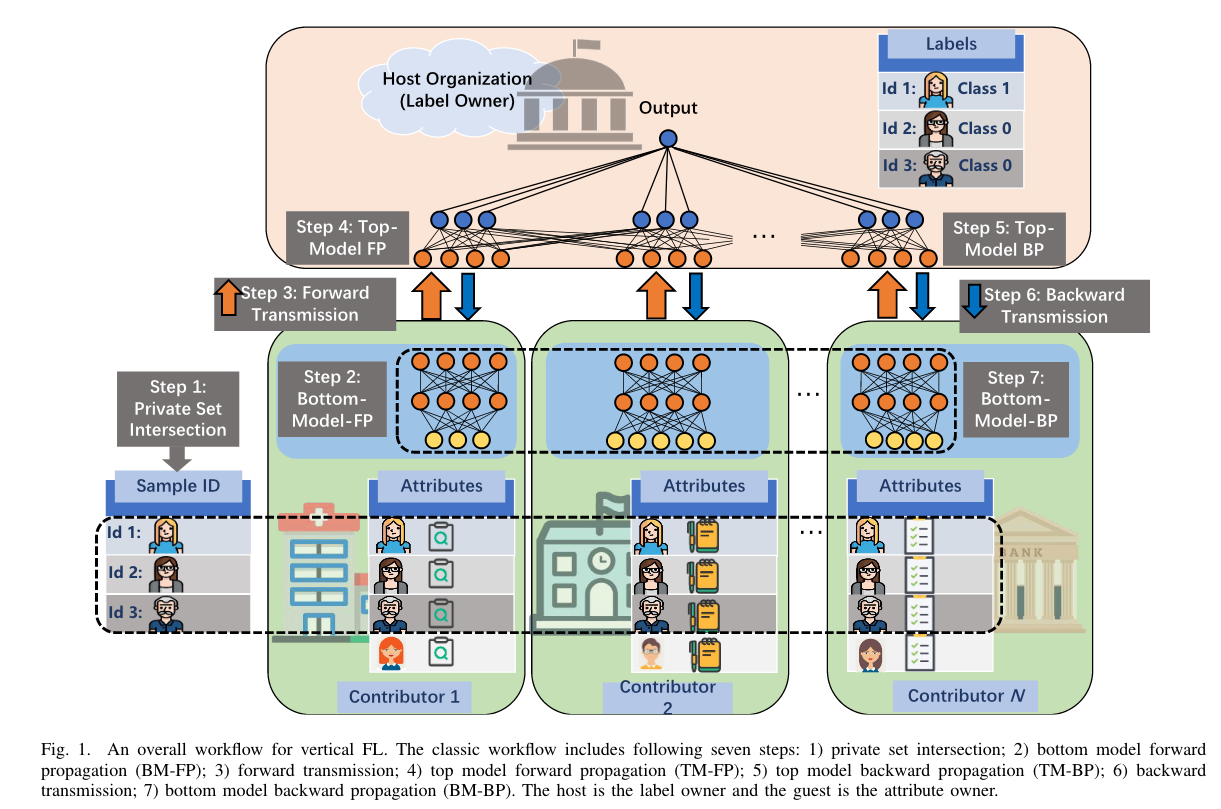
VFL 的关键思想是利用具有各种属性的分布式数据来增强学习模型。因此,VFL 接受垂直划分的数据,其中参与者的数据共享具有不同属性空间的相同样本空间。如上图所示,一般 VFL 过程在每个学习epoch中包括以下七个关键步骤:
- 隐私集求交集:找到所有参与者的公共标识符(ID)以对齐训练数据样本,这称为private set intersection(PSI)或安全实体对齐。广泛采用的 PSI 技术包括朴素哈希、不经意的多项式评估和不经意的传输。
- 底层模型前向传播:每个参与者将基于其底层(本地)模型使用本地数据完成前向传播过程
- 前向输出传输:每个参与者都需要将其前向输出传输给标签所有者。前向输出包含局部神经网络的中间结果,它将原始属性转化为特征。这样的传输过程可能会泄露参与者的隐私信息,应该利用差分隐私 (DP) 等高级隐私保护方法来解决潜在的隐私风险,但可能会产生额外的通信成本和计算复杂性
- 顶层模型前向传播:标签所有者使用从所有参与者收集的输出来计算基于顶层模型和标签的损失函数值。
- 顶层模型反向传播:标签所有者执行反向传播并计算两个梯度:1)顶层模型的模型参数; 2) 每个参与者的前向输出。
- 反向输出传输:前向输出的梯度被发送回每个参与者
- 底层模型反向传播:每个参与者根据本地数据和来自标签所有者的前向输出的梯度计算其底层模型参数的梯度,然后更新其底层模型
2. VFL 和HFL之间的关键差异
下表展示了 VFL 和 HFL 之间的主要区别:
| Framework | 参与者的数据特征 | 交换的信息 | 模型结构 |
|---|---|---|---|
| VFL | 相同的样本空间,但不同的属性空间 | 中间输出及其梯度 | 灵活的、本地保密 |
| HFL | 不同的样本空间,但相同的属性空间 | 全局和本地模型参数 | 固定的、一致的 |
-
数据特征
VFL 和 HFL 之间的这种内在差异导致了截然不同的神经网络结构。一个具体的例子是,HFL 的参与者可能有数百或数千人,而 VFL 的参与者人数通常少于 5 人。
-
交换信息
HFL 的主要特点之一是每个参与者维护一个本地模型并定期接收全局模型的参数。这样,每台机器训练的局部模型是完全相同和完整的,在进行预测时可以独立预测。然而,VFL 中的每个参与者都拥有完整模型的一部分,所有参与者都应该逐个完成一个训练过程。因此,VFL 参与者之间交换的消息是基于底层模型及其梯度的本地数据的中间输出(学习表示),而不是 HFL 中的本地模型参数或更新。
-
模型架构
由于结构不同,通信成本、安全和隐私风险与 HFL 中的有很大不同。例如,VFL 中每个参与者的底层模型结构是灵活的,并且是本地保密的(其他参与者无法获知),这是由拆分方法确定的。在这种情况下,经过精心设计的拆分方法需要适用于特定模型、异构的属性空间以及通信和计算资源。
3. VFL面对的核心挑战
A.安全和隐私风险
现有 VFL 模型的隐私和安全风险研究不足。在 VFL 中,参与者需要获得重合的样本空间,因此来自其他参与者的成员推理攻击可能是多余的。同时一个对抗参与者只控制联邦模型的一部分,不能独立运行,只能访问自己底层模型的梯度。通过分析交换的消息,即中间输出和梯度,参与者可以从其他参与者推断出客户端的属性,例如标签推理攻击和隐私数据泄漏。
- C. Fu et al., “Label inference attacks against vertical federated learning,” in Proc. USENIX Security Symposium (USENIX Security), Boston, MA, Aug. 2022.
- X. Jin et al., “CAFE: Catastrophic data leakage in vertical federated learning,” in Proc. Thirty-fifth Conference on Neural Information Processing Systems (NeurPIS), Virtual Event, Dec. 2021.
现有的隐私保护方法包括 DP、安全多方计算 (SMC)、同态加密 (HE) 及其混合方法,已在 HFL 中广泛采用,但在 VFL 中探索的很少。此外,这些方法还需要在模型性能、隐私和安全级别以及系统效率方面进行精心设计的权衡。 VFL 的一个独特挑战是,拆分方法将决定秘密属性的预处理,即底层模型的前向输出,进而影响隐私和安全级别。对于简单的 ML 模型,例如逻辑回归 (LR) 和核模型,拆分设计很简单,但由于输入的不安全线性过程,隐私保护方法具有相当大的挑战性。如果考虑复杂的神经网络,例如卷积网络,作为底层模型,中间输出将暴露较少的隐私信息。这是因为复杂的非线性函数可以自然地增强分布式数据的隐私性。
从理论上和经验上理解和平衡隐私保护、运行效率和模型性能之间的权衡,是隐私保护 VFL 系统中的一个相当大的挑战。
B. 计算和通信的高开销
尽管在 FL 设置中未明确共享原始数据,但资源有限的通信网络仍然是 HFL 和 VFL 系统中的关键瓶颈 。具体来说,在 VFL 中,总计算和通信成本与训练数据集大小成正比。换句话说,HFL 中广泛采用的批量计算方法不能应用于 VFL。当面对海量数据时,例如数十亿的广告数据,由于硬件容量、带宽和功率等资源有限,通信和本地计算可能会达到许多数量级。
为了适应 VFL 网络中有限的资源条件,因此开发计算和通信高效的方法非常重要,这些方法可以降低计算复杂度,并分别作为训练过程的一部分迭代发送消息或模型更新。
为了进一步降低其中的计算和通信成本,可以考虑三个关键方面:1)修剪神经网络,2)在每一轮训练中通过智能压缩方法减少传输消息的大小,以及 3)选择合适的属性拆分设计.
C.模型划分对结构的破坏
对于各种数据集,最好的训练模型通常是经过精心设计的,但模型拆分过程可能会破坏其特定结构。例如,一些经典的广告数据推荐模型,如 Wide&Deep 和 deepFM,需要计算用户和物品属性之间的余弦相似度来探索它们的相关性。然而,不同的属性值和隐私问题使得难以满足计算余弦相似度的要求。此外,对于包含循环层和注意力层的非常复杂但高效的神经网络模型,例如 transformer,拆分设计在实现隐私保护和通信效率方面变得具有挑战性。
D. 系统异构
每个参与者在存储、硬件(CPU/GPU 和内存)、网络连接(5G 和 wifi)和电源(电池电量)方面的可变性将导致系统异构性。此外,每个参与者的网络规模和系统相关约束通常会导致异步更新 ,即一部分参与者同时处于活动状态。例如,如果一个参与者拥有大量的属性,但传输能力、计算频率或内存大小有限,则很难完成底层模型的前向传播。这些系统级特性极大地带来了挑战,例如掉队者缓解和容错。因此,开发的 VFL 方法必须满足:1) 预期低参与度 2) 容忍异构硬件,以及 3) 足够稳健容忍在一次迭代中丢弃传输的信息
4. 方法与可能的解决方案
本节分析了解决上述挑战的可用技术,并提出了一些可能的解决方案。
A.满足隐私的框架
在 VFL 系统中,安全和隐私问题通常集中在交换的消息上,无论是训练还是服务。因此,保护这些私人信息以及最大化训练效用具有重要意义。一些流行的技术,如 DP、SMC 和 HE,可以用于解决这个问题,但通常会对学习系统造成损害。
差分隐私
差分隐私Differential privacyDP 是基于理论保证提高隐私级别的热门研究方向。与其他隐私增强技术(例如数据混洗)一起,驱动隐私损失的紧密界限有利于在效用和隐私之间获得更好的权衡。具体来说,对于高效率要求,针对推理攻击,DP 将是一个很好的选择,做法是通过噪声扰动反向传播输出或本地底层网络。 S. Abuadbba et al., “Can we use split learning on 1d CNN models for privacy preserving training?” in Proc. ACM Asia Conference on Computer and Communications Security (ASIACCS), Taipei, Taiwan, Oct. 2020, pp. 305–318.
安全多方计算
安全多方计算Secure multi-party computingSMC用于通过涉及加密和协议设计来设计各种隐私保护协议,这对于VFL系统也值得研究,特别是对于有限的通信和计算资源。与DP相比,SMC技术可以保持原有的效用,但由于加密和更多的信息交互而导致更高的计算和通信复杂度。
同态加密
为联邦网络开发安全和隐私方法时,高复杂度是考虑同态加密Homomorphic encryption HE 的关键瓶颈。由于HE允许的运算次数有限,例如加法和乘法,因此非线性运算需要一些精心设计的近似函数,性能损失是不可避免的。幸运的是,它可以被简化或作为协议的一部分用于保护关键消息。
总体而言,隐私、效率和实用性之间始终存在权衡,针对特定客户需求选择适当的隐私和安全技术更为可取。
B. 传输提升
本节将介绍三种降低 VFL 通信成本的经典方案,即传输压缩、模型剪枝和数据采样。
传输压缩
传输压缩。为了降低通信成本,压缩传输消息可以是一种替代方案。具体来说,对于一个 epoch 的训练,VFL 需要两个传输过程,即前向传输和反向传输。对于前向和反向传输,我们可以观察到较大的压缩比会大大降低通信成本,但会涉及较大的训练误差,进而影响底层和顶层模型的更新。与 HFL 不同,大多数经典压缩方案(例如均匀量化)都行不通,因为前向输出的梯度无法在反向传播期间导出。因此,设计一个近似函数来辅助 VFL 中的反向传播将是一个很有前途的方向。建立量化水平和训练性能之间的关系也很重要,这可以为在传输和模型性能之间找到令人满意的权衡提供强有力的指导。
模型剪枝
模型修剪。模型剪枝是减少计算和传输资源的最流行的技术之一。具体来说,我们可以在全连接层或卷积层中丢弃一些不重要的神经元。这样,计算和传输成本将明显降低。因此,进一步研究评估不同神经元或通道的重要性,进而实现具有性能保证的模型剪枝设计具有重要意义。
数据采样
数据采样。也可以采用数据采样来降低通信成本。在传统的 minibatch 机制中,所有的训练数据会被分成几批并打乱,然后 VFL 会逐批训练这些批次。为了降低通信成本,我们可以通过精心设计的过滤机制选择对模型更新很重要的一部分批次。因此,设计数据选择或组合算法以提高 VFL 中的通信效率是一个很有前途的方向。
C.针对异步VFL的新机制
具有异构资源的参与者可能会出现异步,需要智能分配器或补偿算法来提高训练性能。异步通信已经在 HFL 中针对落后者和异构延迟的许多方面进行了研究,例如平均方法的权重设计和更新补偿。在 VFL 中,每个参与者都拥有一个独特的属性集,其前向输出与其他参与者截然不同。如果某些参与者在一个 epoch 落后,可以使用历史信息(以前的输出)来训练这个 epoch 作为替代方法。此外,在实际场景中,参与者通常在属性空间上存在一些重叠,可以探索这些重叠来应对这一挑战。
D. 划分设计
VFL 模型的拆分方法是影响训练性能、通信和计算分配以及隐私风险的关键技术。
对通信和计算的影响
对于一种经典的学习模型,拆分设计将直接影响参与者的训练任务分配和传输成本。此外,底层模型的简单结构,如线性计算层,会带来很高的隐私风险,需要进一步的隐私保护,增加通信和计算成本。总体而言,需要针对不同参与者和模型在切割/拆分层上进行个性化设计,以确保计算和通信效率。
对安全和隐私的影响
拆分规则决定了传输消息的类型,需要在学习过程中进行保护。为底层模型引入隐私保护和复杂性可接受性神经网络结构可能是一种替代方案。
对模型性能的影响
一些设计良好的学习结构需要提取原始属性之间的关系,例如 Wide&Deep 和 DeepFM。然而,VFL 要求每个参与者将他们的原始数据保存在本地。因此,我们应该在保持这些特定结构的同时设计划分方法,并设计有效的层或交互机制来补偿划分连接造成的损害。
5. 总结
本文从四个方面研究了 VFL 中的潜在挑战和独特问题,即安全和隐私风险、昂贵的计算和通信成本、结构损坏和系统异构性。主要指出了,划分设计要适应模型的特定结构,同时也会影响整个VFL系统的隐私和安全保护以及计算和通信效率。此外,对于设计VFL系统时所考虑的问题讨论了可能的解决方案。