根据Jax&Jax环境配置(一):基于Docker配置环境的操作过程,配置好jax和jax_privacy的环境之后就可以运行相应的示例代码验证环境是否搭建成功,下面将分别jax的示例代码和jax_privacy的示例代码。
本文由本人完成,引用的话标注来源,欢迎随意转载阅读^ - ^
jax的示例代码
可以运行下面这个在8个GPU上跑的脚本进行测试
from jax import random, pmap
import jax.numpy as jnp
#Create 8 random 5000 x 6000 matrices, one per GPU
keys = random.split(random.PRNGKey(0), 8)
mats = pmap(lambda key: random.normal(key, (5000, 6000)))(keys)
#Run a local matmul on each device in parallel (no data transfer)
result = pmap(lambda x: jnp.dot(x, x.T))(mats) # result.shape is (8, 5000, 5000)
#Compute the mean on each device in parallel and print the result
print(pmap(jnp.mean)(result))
#prints [1.1566595 1.1805978 ... 1.2321935 1.2015157]
还可以运行 jax/examples/下的mnist_classifier.py示例
A basic MNIST example using JAX with the mini-libraries stax and optimizers.
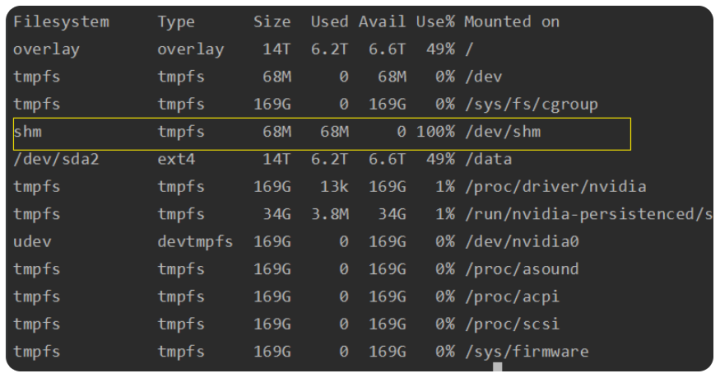
这里有可能如果遇到Bus error (core dumped)这个报错
[解决方法] 原因是在 docker 运行的时候,shm 分区设置太小导致 share memory 不够。不设置 –shm-size 参数时,docker 给容器默认分配的 shm 大小为 68M,导致程序启动时不足。所以务必在启动docker的时候加上–shm-size参数并指定一个大的值(比如 –shm-size 16G)。如果未指定该参数,又想要改变当前容器的shm值,可以根据以下教程的方法二进行操作,同样可以修改。
https://blog.csdn.net/wd18508423052/article/details/116306096
运行示例将会获得类似如下输出
Epoch 0 in 11.04 sec
Training set accuracy 0.8965833187103271
Test set accuracy 0.9007999897003174
Epoch 1 in 2.52 sec
Training set accuracy 0.9230833649635315
Test set accuracy 0.9188999533653259
Epoch 2 in 2.52 sec
Training set accuracy 0.9352333545684814
Test set accuracy 0.9286999702453613
Epoch 3 in 2.53 sec
Training set accuracy 0.9432833194732666
Test set accuracy 0.9348999857902527
Epoch 4 in 2.53 sec
Training set accuracy 0.9490333199501038
Test set accuracy 0.9384999871253967
Epoch 5 in 2.53 sec
Training set accuracy 0.9531999826431274
Test set accuracy 0.9430999755859375
Epoch 6 in 2.53 sec
Training set accuracy 0.9570333361625671
Test set accuracy 0.9456999897956848
Epoch 7 in 2.53 sec
Training set accuracy 0.9610166549682617
Test set accuracy 0.9488999843597412
Epoch 8 in 2.53 sec
Training set accuracy 0.9636000394821167
Test set accuracy 0.9506999850273132
Epoch 9 in 2.53 sec
Training set accuracy 0.965583324432373
Test set accuracy 0.9526000022888184
jax_privacy的示例代码
jax_privacy的示例为在Cifar10数据集上训练具有epsilon=1的隐私保护的wideresnet网络,对应的config 文件位于jax_privacy/experiments/image_classification/configs/cifar10_wrn_16_4_eps1.py路径下,代码位于jax_privacy/experiments/imageclassification/run_experiment.py路径下
step1.将这两文件拷贝到jax_privacy目录下面
step2.提前准备数据集
运行示例代码依赖于tensorflow_datasets来导入数据,会自动下载相应数据集,但会因为网络问题下载失败。这里采用以下知乎回答中的方法二,使用colab下载数据集到本地,然后再传输到服务器相应的位置,可以解决这个问题。https://www.zhihu.com/question/362309074/answer/1684354563
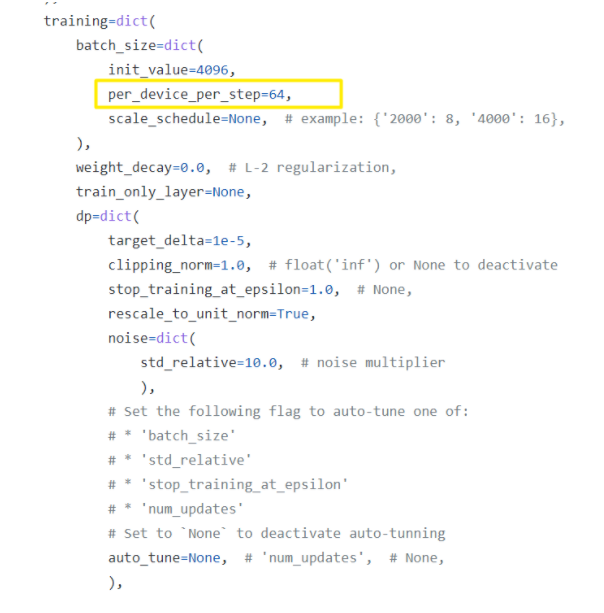
step3. 调整训练per_device_per_step大小
最后运行以下命令,注意原始配置文件cifar10_wrn_16_4_eps1.py
如果你在默认配置下观察到内存不足的错误,可以考虑减少config.experiment_kwargs.config.training.batch_size.per_device_per_step的值,以确保每个时间步骤处理的样本数量适合内存大小。不过这样会使训练速度变慢,但不会改变每个模型更新所使用的有效batchsize大小。同时注意,config.experiment_kwargs.config.training.batch_size.init_value应该能被per_device_per_step整除,这里将per_device_per_step值修改成32
step4. GPU的使用与分配
这时直接按照README运行,会发现出现OOM的报错
【解决方法】参考https://www.bookstack.cn/read/TensorFlow2.0/spilt.6.3b87bc87b85cbe5d.md 设置显存使用策略,在run_experiment.py代码中加入下面几行代码即可
os.environ['CUDA_VISIBLE_DEVICES'] = '4,5'
physical_devices = tf.config.experimental.list_physical_devices('GPU')
assert len(physical_devices) > 0, "Not enough GPU hardware devices available"
for gpu in physical_devices:
tf.config.experimental.set_memory_growth(gpu, True)
step5. 开始训练
python run_experiment.py --config=cifar10_wrn_16_4_eps1.py --jaxline_mode=train_eval_multithreaded
可以成功运行的话,就大功告成!!