本文将介绍如何基于Ubuntu中的Docker搭建支持CPU和NVidia GPU的jax和jax_privacy运行环境,其中官方开源代码已给出了基本的安装操作步骤,可以参考下面链接查看文档
但是,正如文档中提及的,如果想安装同时支持CPU和Nvidia GPU的JAX,必须事先将 CUDA和CuDNN安装好。与其他一些流行的深度学习库不同的是,JAX没有将CUDA或CuDNN作为 pip 包的一部分依赖来捆绑安装。因此接下来的介绍将包括几个核心的部分:
- 基于Docker配置环境的操作过程(一)
- 在Docker环境中CUDA和CUDNN的注意事项(一)
- 运行JAX示例代码(二)
本文由本人完成,引用的话标注来源,欢迎随意转载阅读^ - ^
相关概念
首先介绍几个之后会提及的概念
-
CUDA:为“GPU通用计算”构建的运算平台。
-
cudnn:为深度学习计算设计的软件库。
-
CUDA Toolkit (nvidia): CUDA完整的工具安装包,其中提供了 Nvidia 驱动程序、开发 CUDA 程序相关的开发工具包等可供安装的选项。包括 CUDA 程序的编译器、IDE、调试器等,CUDA 程序所对应的各式库文件以及它们的头文件。
-
CUDA Toolkit (Pytorch): CUDA不完整的工具安装包,其主要包含在使用 CUDA 相关的功能时所依赖的动态链接库。不会安装驱动程序。
-
Docker 是一个构建,发布和运行应用程序的开放平台。Docker 以容器(container)为资源分隔和调度的基本单位,容器封装了整个项目运行时所需要的所有环境,通过 Docker 你可以将应用程序与基础架构分离,像管理应用程序一样管理基础架构,以便快速完成项目的部署与交付。 Docker的三个核心概念:
- 容器(Container):容器类似于一个轻量级的沙箱,Docker利用容器来运行和隔离应用。
- 镜像(Image):镜像类似于虚拟机镜像,你可以将其理解为一个只读模板。
- 镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的 类 和 实例 一样,镜像是静态的定义,容器是镜像运行时的实体,容器可以被创建、启动、停止、删除、暂停等。
- 仓库(Registry),docker仓库类似于代码仓库,它是docker集中存放镜像文件的场所。Docker Hub 是 Docker 官方提供的镜像公有仓库,提供了大量常用软件的镜像
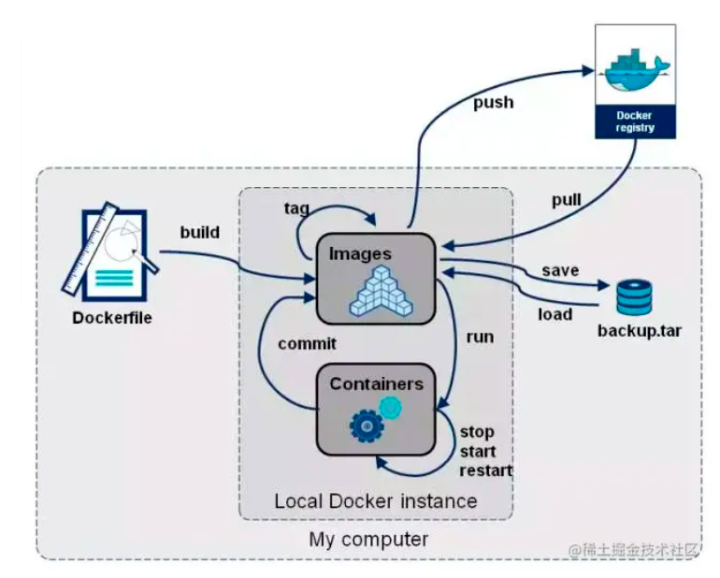
基于Docker配置环境的操作过程
采用Docker作为配置环境的出发点是,正如上面介绍到的,Docker是一个能够与原始环境隔离的虚拟环境,也就是在docker容器中的任何操作都不会影响到原始环境,同时docker镜像仓库提供了很多公开的镜像库,其中很多都是已经集成了需要的依赖,在这些基础上去配置环境可以方便许多,也不用担心影响到已经存在的其他环境。关于docker的基本操作可以参考相关文档,下面用到什么命令才会加以介绍。
JAX对于CUDA和CUDNN的版本要求:

根据JAX的要求,接下来的目标就是在搭建jax/jax_privacy所需的CUDA和cuDNN环境,以及jax包的安装。接下来依次介绍几个关键步骤:
(1)查看Ubuntu版本
首先查看平台的Ubuntu版本,查看目录”/proc”下version的信息,可以得到当前系统的内核版本号及系统名称 。
运行cat /proc/version
Linux version 4.15.0-177-generic (buildd@ubuntu) linux内核版本号
(gcc version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)) gcc编译器版本号
#186-Ubuntu SMP Thu Apr 14 20:23:07 UTC 2022
(2) 安装 Docker 并检查是否正在运行
接着就是在Ubuntu中安装docker,本人环境中之前就安装过docker,这一步可以参考 https://yeasy.gitbook.io/docker_practice/install/ubuntu进行。
Docker 已经安装完毕,我们启动守护程序,然后检查 Docker 是否正在运行
运行 sudo systemctl status docker,执行结果类似以下内容,说明该服务处于活动状态并且正在运行:
docker.service - Docker Application Container Engine
Loaded: loaded (/lib/systemd/system/docker.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2022-07-22 04:38:15 UTC; 3 days ago
Docs: https://docs.docker.com
Main PID: 29857 (dockerd)
Tasks: 82
CGroup: /system.slice/docker.service
└─29857 /usr/bin/dockerd --registry-mirror=https://y0sj1ywh.mirror.aliyuncs.com -H fd:// --containerd=/run/containerd/containerd.sock
(3)配置Docker的registry-mirror
可以注意到上面输出中的–registry-mirror=https://y0sj1ywh.mirror.aliyuncs.com,说明已经配置了拉取时候的镜像地址,因为采用docker原始的镜像源拉取镜像非常慢,并且时常出现网络问题,这里务必改成国内的镜像。可以参考https://yeasy.gitbook.io/docker_practice/install/mirror这个教程进行镜像加速器的配置.
请首先执行以下命令,查看是否在 docker.service 文件中配置过镜像地址
systemctl cat docker | grep '--registry-mirror'
我这里输出了如下信息,说明已经配置过https://y0sj1ywh.mirror.aliyuncs.com镜像源
ExecStart=/usr/bin/dockerd --registry-mirror=https://y0sj1ywh.mirror.aliyuncs.com -H fd:// --containerd=/run/containerd/containerd.sock
这里需要注意的一点是,如果参考教程利用/etc/docker/daemon.json配置的话,要先修改/lib/systemd/system/docker.service对应的文件内容去掉 --registry-mirror 参数及其值,再进行配置。
不然保留/lib/systemd/system/docker.service中 --registry-mirror 参数及其值,同时再配置/etc/docker/daemon.json的话,当重启docker会引起如下的报错,说明docker重启失败
sudo systemctl restart docker
`Job for docker.service failed beca use the control process exited with error code.`
`See "systemctl status docker.service" and "journalctl -xe" for details.`
当完成教程中的步骤之后,成功执行以下两条命令没有多余的输出,说明已经配置成功。
sudo systemctl daemon-reload
sudo systemctl restart docker
(4)docker hub找符合需求的镜像
可以先注册一个账号,然后登陆,之后在服务器上也会用到
在docker hub中可以直接搜索关键词搜索符合需求的镜像,由于jax_privacy相关说明提到需要tensorflow的环境,jax需要符合版本的CUDA和CuDNN,我们这里可以选用https://hub.docker.com/r/tensorflow/tensorflow这个镜像列表中满足需求的那一个:
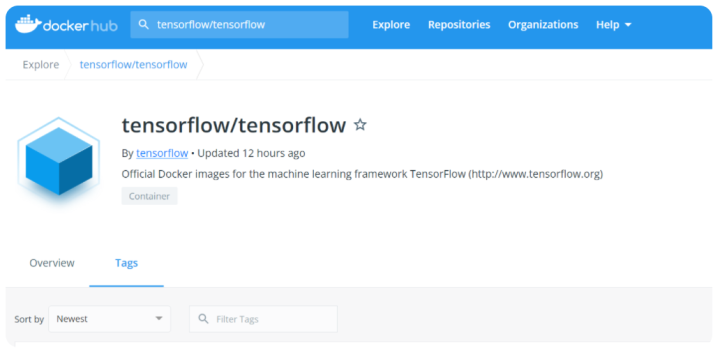
其中Overiew介绍了TensorFlow Docker Images的基本信息,和给出的base tag的解释,这里我们选用了nightly-gpu这个TAG对应的images
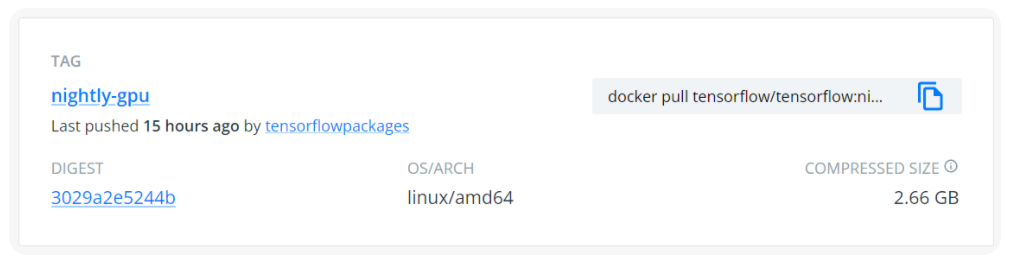
查看IMAGE LAYERS,CUDA的版本为11.2,CUDNN的版本为8.1满足JAX的要求:
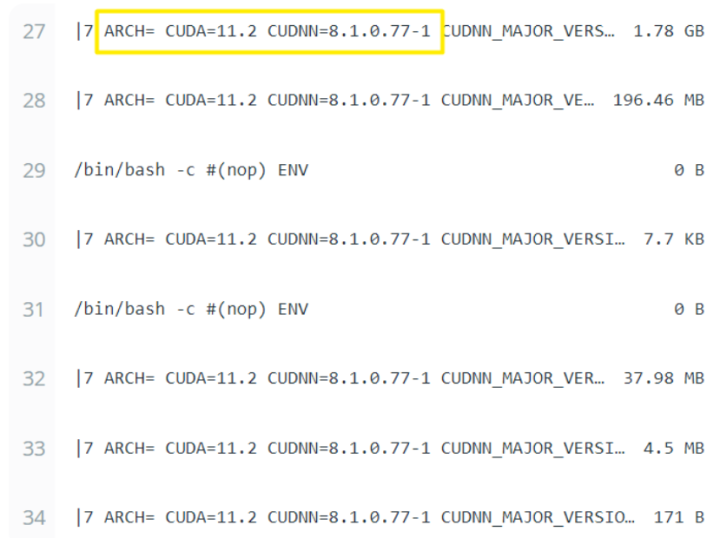
(5)拉取镜像
docker pull : 从镜像仓库中拉取或者更新指定镜像
| docker pull [OPTIONS] NAME[:TAG | @DIGEST] |
OPTIONS说明:
-
-a :拉取所有 tagged 镜像
-
–disable-content-trust :忽略镜像的校验,默认开启
-
–platform: 如果服务具有多平台功能,则设置平台;
-
-q:一直详细输出;
TAG:标签(版本);
DIGEST:摘要
使用 docker pull 命令下载一个指定的镜像或一组镜像(例如,一个存储库),如果没有提供标签,Docker Engine 默认使用:latest标签。这个命令拉出最新的发行版镜像;
这里我们通过运行docker pull tensorflow/tensorflow:nightly-gpu 就可以拉取镜像
但是这里需要注意,直接通过可能会导致拉取的镜像不是目前看到的版本,如果之前拉取过tensorflow/tensorflow:nightly-gpu 这个镜像,会导致新拉取的镜像里面的环境还是原先的,所以应该在后面指定DIGEST也就是下面黄色方框的编码:
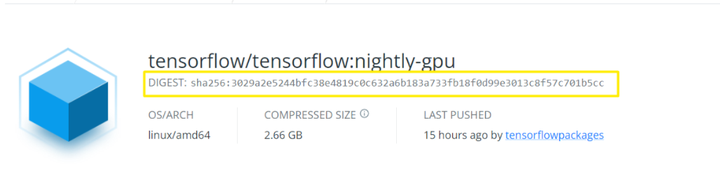
https://stackoverflow.com/questions/59671793/pulling-docker-image-by-digest/63204994
最终需要运行的docker pull 命令为
docker pull tensorflow/tensorflow:nightly-gpu@sha256:3029a2e5244bfc38e4819c0c632a6b183a733fb18f0d99e3013c8f57c701b5cc
拉取完镜像我们可以通过用 docker images 来列出本地主机上的镜像,将会获得如下类似输出,其中第一行为拉取的image:
REPOSITORY TAG IMAGE ID CREATED SIZE
tensorflow/tensorflow <none> e3a229c14578 5 days ago 5.97GB
tensorflow/tensorflow latest-devel-gpu 446020ce6b9e 10 days ago 6.75GB
ssdog/cuda 11.6.2-runtime-ubuntu20.04.py38 b878249a9062 3 weeks ago 4.01GB
nvidia/cuda 11.3.1-cudnn8-runtime-ubuntu18.04 b9b06e98b7ff 2 months ago 3.3GB
nvidia/cuda 11.0.3-base-ubuntu20.04 d134f267bb7a 2 months ago 122MB
informer latest 3aa9111a7e5d 8 months ago 2.6GB
vivekratnavel/omniboard latest 1fd8598f7a0f 12 months ago 168MB
各个选项说明:
-
REPOSITORY:表示镜像的仓库源
-
TAG:镜像的标签
-
IMAGE ID:镜像ID
-
CREATED:镜像创建时间
-
SIZE:镜像大小
(6) 运行容器
docker run [OPTIONS] IMAGE [COMMAND] [ARG…]
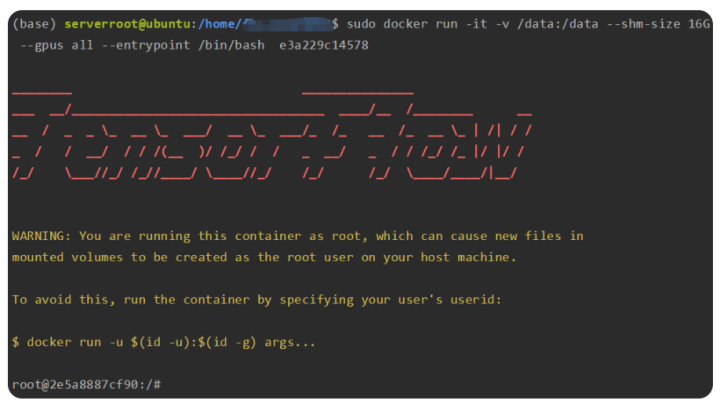
docker run -it -v /data:/data --gpus all --shm-size 16G --entrypoint /bin/bash e3a229c14578
各个选项说明:
-
-i: 交互式运行容器,通常与-t同用
-
-t: 终端,为容器分配命令行,通常与-i同用
-
-v :目录映射,容器目录挂载到宿主机目录,格式:
:<容器目录> -
–entrypoint /bin/bash:进入/bin/bash交互式 Shell
-
–gpus all:所有gpu都可以用,在Docker 19.03或更高版本中,设置该选项使得容器中能够使用GPU
-
–shm-size:shm(share memory) 给容器的shm分区设置 空间大小,如果不设置该值会在后面运行程序的时候出现Bus error (core dumped)报错,具体可以看3(1)运行jax示例的部分
-
e3a229c14578为上面拉取的镜像的ID
运行上述命令,就可以进入到容器中,如下所示其中左下角的编码为当前容器的ID
(7) CUDA相关操作
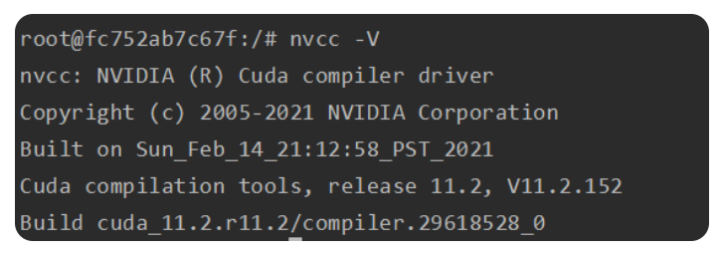
通过运行nvcc -V查看当前环境中CUDA的版本,可以看到为11.2符合预期
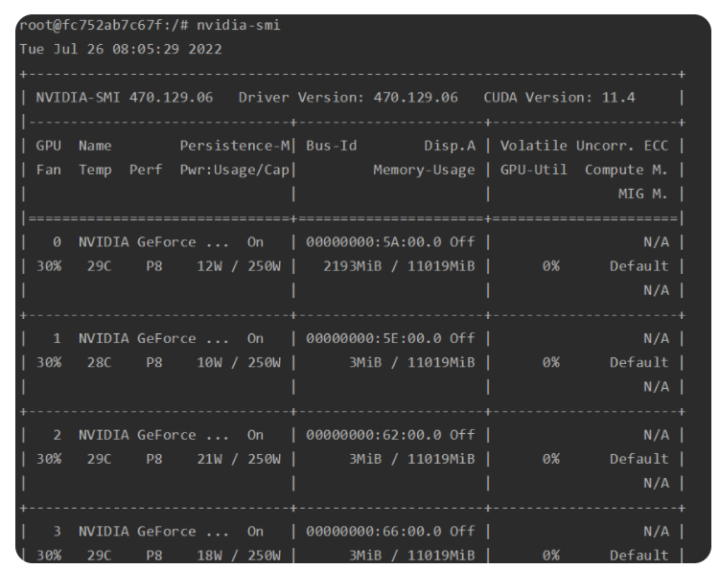
查看NVIDIA动态使用情况: nvidia-smi,其中CUDA Version主要指的是能够支持的最高的CUDA版本,而当前环境为 11.2<11.4 没有问题。
验证TensorFlow是否可以调用GPU
tf.config.list_physical_devices('GPU')
没有问题
import tensorflow as tf
tf.config.list_physical_devices('GPU')
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU'),
PhysicalDevice(name='/physical_device:GPU:1', device_type='GPU'),
PhysicalDevice(name='/physical_device:GPU:2', device_type='GPU'),
PhysicalDevice(name='/physical_device:GPU:3', device_type='GPU'),
PhysicalDevice(name='/physical_device:GPU:4', device_type='GPU'),
PhysicalDevice(name='/physical_device:GPU:5', device_type='GPU'),
PhysicalDevice(name='/physical_device:GPU:6', device_type='GPU'),
PhysicalDevice(name='/physical_device:GPU:7', device_type='GPU')]
cuda默认安装在/usr/local目录,可以使用ls -l /usr/local 查看该目录下有哪些cuda版本,以下输出表示当前机器上安装了11.0和11.2两个cuda版本,/usr/local/cuda是一个软链接,链接到了/usr/local/cuda-11.2目录,表示当前使用的是cuda-11.2版本。
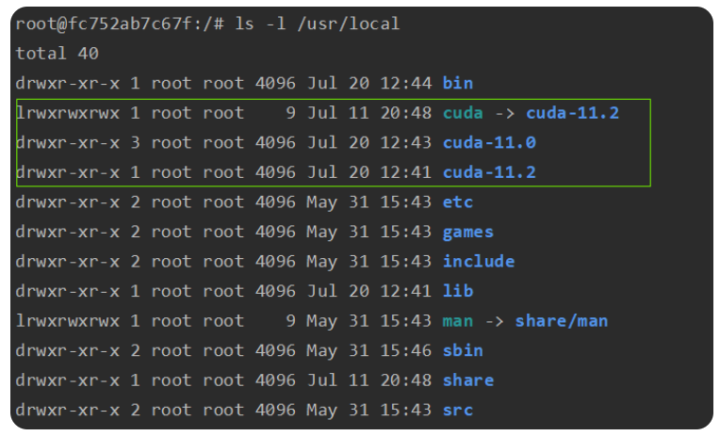
更多手动安装CUDA和切换CUDA版本的操作可以参考以下链接
https://bbs.huaweicloud.com/blogs/140384
(8)CUDNN相关操作
通过cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2 命令查看cuDNN版本号,发现这个容器中没有CUDNN,同时确认了/usr/local/cuda/include路径下以及/usr/local/cuda/lib64下都没有cudnn相关的文件

所以这里需要去自己安装CUDNN==,不过好在cuDNN安装起来挺简单的
进入下载页面https://developer.nvidia.com/rdp/cudnn-archive
一定一定选择与CUDA适配的CUDNN进行下载,这里我选用的是适配11.2的cuDNN v8.1.0
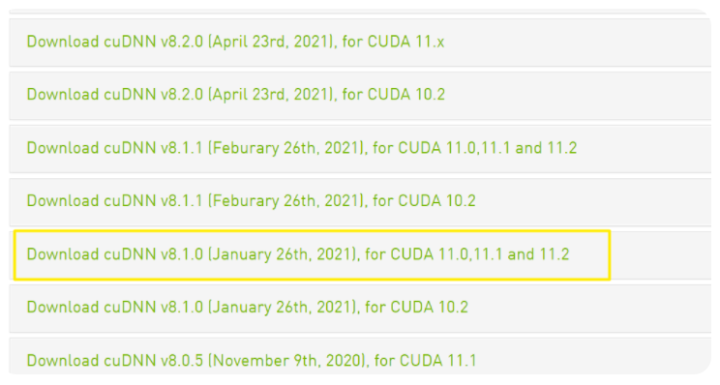
P.S. 之前试过使用 cuDNN v8.2.1,以为CUDA11.X是满足CUDA11.0 CUDA11.1 CUDA11.2….的CUDNN版本但是这个会引起之后运行jax_privacy代码的各种各样的报错达咩达咩

下载完获得压缩包,在安装环境解压获得一个cuda文件夹,进入到这个文件中,然后运行以下命令就可以完成cuDNN的安装
cp include/* /usr/local/cuda/include
cp lib64/libcudnn* /usr/local/cuda/lib64
chmod 777 /usr/local/cuda/include/cudnn*.h
chmod 777 /usr/local/cuda/lib64/libcudnn*
再次通过cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2 这个命令就可以查看到cuDNN版本号
cat /usr/include/cudnn.h |grep CUDNN_MAJOR -A 2
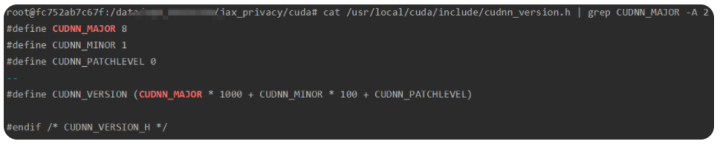
(9)JAX的安装
根据JAX开源库的README 中Installation, pip installation: GPU (CUDA)的部分
注意我们这里的CUDA为11.2,cuDNN为8.1.0,而运行pip install jax[cuda]将会默认安装满足CUDA为11并且cuDNN版本大于8.2的jax[cuda],因此不可以直接通过下列方式安装,不然同样会引起许多花式报错。
pip install --upgrade pip
Installs the wheel compatible with CUDA 11 and cuDNN 8.2 or newer.
Note: wheels only available on linux.
pip install --upgrade "jax[cuda]" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
我这里的环境满足Cuda >= 11.1和cudnn >= 8.0.5,所以可以通过以下命令行安装对应的jax
pip install --upgrade pip
Installs the wheel compatible with Cuda >= 11.1 and cudnn >= 8.0.5
pip install "jax[cuda11_cudnn805]" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
安装好jax 之后可以验证一下jax是否可以调用GPU
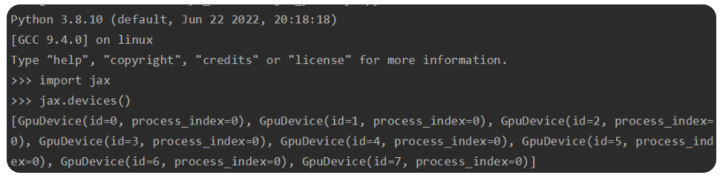
(10)jax_privacy
jax_privacy使用https://github.com/deepmind/jax_privacyinstallation的Option 2进安装,按照README操作即可。
首先就是将jax_privacy repo clone到本地里面
git clone https://github.com/deepmind/jax_privacy
然后运行下面的命令即可,这样对代码库的本地修改就会反映在导入的包中
cd jax_privacy
pip install -e .
这一步会通过pip来安装requirements.txt里面的包,时常发生以下GnuTLS recv error (-110): The TLS connection was non-properly terminated.参考https://blog.csdn.net/qq_37637196/article/details/125486424
解决方法(顺序执行以下代码):
apt-get install gnutls-bin
git config --global http.sslVerify false
git config --global http.postBuffer 1048576000
到这里jax和jax_privacy的环境已安装基本构建完成,下面我们在这个环境中运行一些示例脚本进行进一步的测试。
(11)将容器转成镜像
上面整个过程还是比较繁琐的,所以希望可以将配置好的环境保存下来,当我们创建一个新的容器的时候可以相当于完整拷贝当前的容器环境,,Docker 提供了 commit 命令支持将容器重新打成镜像文件,其命令格式如下所示
docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]]
Option
- -a指定新镜像作者
- -c使用 Dockerfile 指令来创建镜像
- -m提交生成镜像的说明信息
- -p在 commit 时,将容器暂停
当我们将上面配置好环境的容器,打成镜像,再运行该镜像就可以得到一个完全支持JAX的新的容器。